
dom [перевод]
Вольный перевод статьи из блога chromium.googlesource "DOM"
DOM
Директория renderer/core/dom содержит имплементацию DOM.
В принципе, эта директория должна содержать только файл, который имеет отношение к DOM Standard. Однако, по историческим причинам, директория renderer/core/dom использовалась для разных файлов*.* В результате, к сожалению, она содержит множество файлов, напрямую к DOM не относящихся.
Потому, пожалуйста, больше не добавляйте не имеющие отношения к DOM файлы в эту директорию. Мы пытаемся их организовать таким образом, чтобы разработчики не путались, разбирая её.
- Используйте таблицу, как строгий план по организации файлов исходников/ядра/dom.
- Для отслеживания наших стараний, смотрите crbug.com/738794.
Узел и дерево узлов
В этом README мы изобразим дерево с направлением слева-направо в ascii-art системе. A - корень дерева.
A ├───B ├───C │ ├───D │ └───E └───F
Node - это базовый класс всех видов узлов в дереве. Каждый Node имеет следующие три указателя (но ими не ограничивается):
parent_or_shadow_host_node_: Указывает на родителя (или теневого родителя, если корень теневой)previous_: Указывает на предыдущего родственникаnext_: Указывает на следующего родственника
ContainerNode, от которого отходит Element, имеет дополнительные указатели на своих потомков:
first_child_: Очевидно.last_child_: Тоже.
Это означает:
- Родственники хранятся в виде связного списка. Запрашивает O(N), чтобы добраться до n-го потомка родителя.
- Родители не может сказать, скольких потомков имеет за O(1).

Далее:
Node,ContainerNode
C++11 основанные на диапазоне for циклы для обхода дерева
Вы можете пройти по дереву вручную:
// In C++
// Обход потомка. for (Node* child = parent.firstChild(); child; child = child->nextSibling()) { ... }
// ...
// Обход узлов в древовидном порядке, обход в глубину. void foo(const Node& node) { ... for (Node* child = node.firstChild(); child; child = child->nextSibling()) { foo(*child); // Recursively } }
Древовидный порядок это :
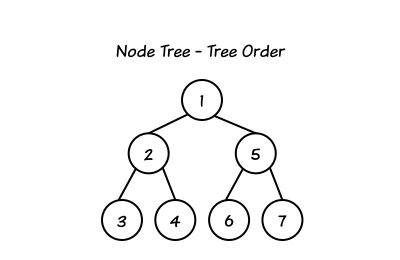
Однако, обход дерева таким образом может быть подвержен ошибкам. Вместо этого вы можете использовать NodeTraversal и ElementTraversal. Они предоставляют основанные на диапазоне C++11 for циклы, такие как:
// В C++ for (Node& child : NodeTraversal::childrenOf(parent) { ... }
// В C++ for (Node& node : NodeTraversal::startsAt(root)) { ... }
Например, для данного родителя A, проход по B, C и F в данном порядке. Есть несколько полезных for циклов для разных целей. Цена таких циклов равна нулю, поскольку все может быть инлайновым.
Далее:
NodeTraversalиElementTraversal(более безопасная версия)- CL, который представил эти for циклы
Теневое дерево (Shadow Tree)
Теневое дерево - это дерево узлов с корнем ShadowRoot. С точки зрения веб разработчика, теневой корень может быть создан вызовом element.attachShadow{ ... } API, где element является теневым предком (shadow host) или простым предком, если контекст чист.
- shadow root всегда присоединен к другому дереву узлов через своего предка. Потому shadow tree никогда не одиноко.
- на дерево узлов предка теневого корня иногда ссылаются, как на light tree.
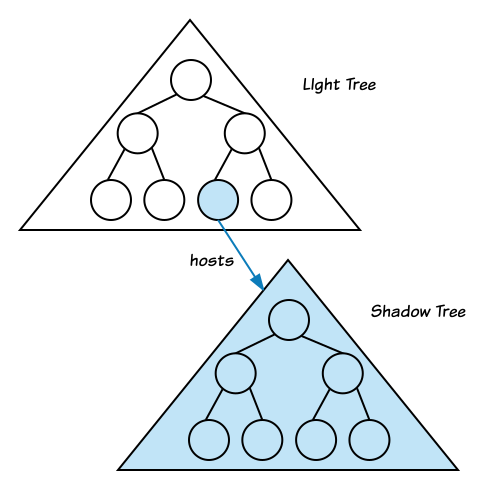
Например, для такого дерева:
A ├───B ├───C │ ├───D │ └───E └───F
веб разработчики могут создавать теневой корень и манипулировать теневым деревом следующим образом:
// В JavaScript const b = document.querySelector('#B'); const shadowRoot = b.attachShadow({ mode: 'open' }); const sb = document.createElement('div'); shadowRoot.appendChild(sb);
В результате теневым деревом будет:
shadowRoot └── sb
shadowRoot имеет одного потомка sb. Это теневое дерево прикреплено к B:
A └── B ├──/shadowRoot │ └── sb ├── C │ ├── D │ └── E └── F
В этой статье нотация (──/) используется для представления отношений shadowhost-shadowroot в составном дереве, о котором речь пойдет позже. shadowhost-shadowroot - это 1:1 отношения.
Хоть теневой корень всегда имеет соответствующий элемент теневого предка, легкое и теневое дерево должны рассматриваться отдельно, с точки зрения дерева узлов. (──/) НЕ показывает отношение предок-потомок в дереве узлов.
Например, даже если B содержит теневое дерево, shadowRoot не считается потомком B. Под следующими обходами:
// В C++ for (Node& node : NodeTraversal::startsAt(A)) { ... }
подразумеваются только A, B, C, D, E и F узлы. Они никогда не попадут ни в shadowRoot, ни в sb. NodeTraversal никогда не пересечет теневую границу ──/.
Дальше:
ShadowRootElement#attachShadow
TreeScope
Document и ShadowRoot всегда являются корнями дерева узлов. ОбаDocument и ShadowRoot реализуют TreeScope.
TreeScope хранит множество информации о нижележащем дереве для эффективности. Например, TreeScope имеет id-to-element отображение, такое как [TreeOrderedMap](https://chromium.googlesource.com/chromium/src/+/master/third_party/blink/renderer/core/dom/tree_ordered_map.h), потому querySelector('#foo') может найти элемент с id “foo” за O(1). Другими словами, root.querySelector('#foo') может быть медленным, если используется в дереве, корнем которого не является TreeScope.
Каждый Node имеет tree_scope_ указатель, который ссылается на:
- Корневой узле: если корнем узла является Document или ShadowRoot.
- owner document, в противном случае.
Это значит, что указатель tree_scope_ всегда non-null (кроме случаев, когда присутствует мутация в DOM), но не всегда ссылается на корень узла.
Поскольку не у каждого узла есть указать, который всегда ссылается на корень, Node::getRootNode(...) может выполняться за O(N), если узел не находится ни в дереве документа, ни в теневом дереве. Если узел в TreeScope (Node#IsInTreeScope() может об этом сказать), мы можем получить корень за O(1).
У каждого узла есть флаги, которые обновляются при изменении DOM, потому мы можем определить, находится он в дереве документа, теневом дереве или ни в одном из них, с помощью Node::IsInDocumentTree() и/или Node::IsInShadowTree().
Если вам нужно добавить новую функциональность в Document, он может оказаться неудачным для того местом. Вместо этого, пожалуйста, рассмотрите возможность добавления ее в TreeScope. Мы хотим, чтобы и теневое, и легкое деревья обрабатывались как можно более одинаково.
Пример
document └── a1 ├──/shadowRoot1 │ └── s1 └── a2 └── a3
document-fragment └── b1 ├──/shadowRoot2 │ └── t2 └── b2 └── b3
- И так, у нас есть 4 дерева; корневой узел каждого - это document, shadowRoot1, document-fragment и shadowRoot2.
- Предполагаем, что каждый узел был создан с помощью
document.createElement(...)(кроме Document и ShadowRoot). Это означает, что владельцем каждого узла является document.
| node | node's root | node's _tree_scope points to: |
|---|---|---|
| document | document (self) | document (self) |
| a1 | document | document |
| a2 | document | document |
| a3 | document | document |
| shadowRoot1 | shadowRoot1 (self) | shadowRoot1 (self) |
| s1 | shadowRoot1 | shadowRoot1 |
| document-fragment | document-fragment (self) | document |
| b1 | document-fragment | document |
| b2 | document-fragment | document |
| b3 | document-fragment | document |
| shadowRoot2 | shadowRoot2 (self) | shadowRoot2 (self) |
| t1 | shadowRoot2 | shadowRoot2 |
Дальше:
[tree_scope.h](https://chromium.googlesource.com/chromium/src/+/master/third_party/blink/renderer/core/dom/tree_scope.h),[tree_scope.cc](https://chromium.googlesource.com/chromium/src/+/master/third_party/blink/renderer/core/dom/tree_scope.cc)Node#GetTreeScope(),Node#ContainingTreeScope(),Node#IsInTreeScope()
Составное дерево
Глядя на прошлое изображение, вы могли подумать, что деревья узлов, дерево документа и теневое дерево были соединены друг с другом. В каком-то смысле, это так. Мы называем его составным деревом, которое является деревом деревьев.
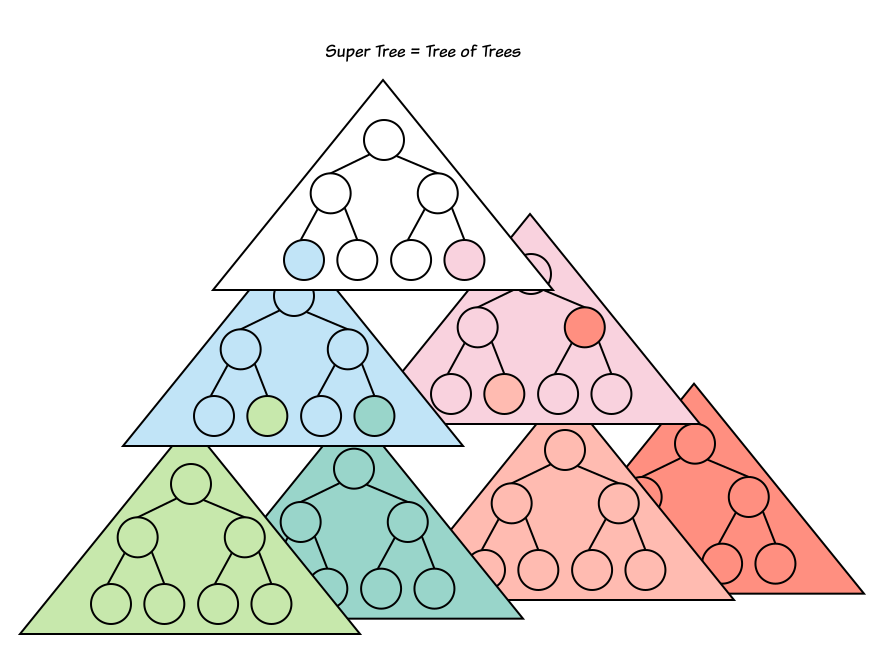
Ниже приведен пример:
document ├── a1 (host) │ ├──/shadowRoot1 │ │ └── b1 │ └── a2 (host) │ ├──/shadowRoot2 │ │ ├── c1 │ │ │ ├── c2 │ │ │ └── c3 │ │ └── c4 │ ├── a3 │ └── a4 └── a5 └── a6 (host) └──/shadowRoot3 └── d1 ├── d2 ├── d3 (host) │ └──/shadowRoot4 │ ├── e1 │ └── e2 └── d4 (host) └──/shadowRoot5 ├── f1 └── f2
Если вы посмотрите внимательно, то сможете заметить, что составное дерево состоит из шести деревьев узлов, одного дерева документа и пяти теневых деревьев:
-
дерево документа
document ├── a1 (host) │ └── a2 (host) │ ├── a3 │ └── a4 └── a5 └── a6 (host)
-
теневое дерево 1
shadowRoot1 └── b1
-
теневое дерево 2
shadowRoot2 ├── c1 │ ├── c2 │ └── c3 └── c4
-
теневое дерево 3
shadowRoot3 └── d1 ├── d2 ├── d3 (host) └── d4 (host)
-
теневое дерево 4
shadowRoot4 ├── e1 └── e2
-
теневое дерево 5
shadowRoot5 ├── f1 └── f2
Если рассматривать каждое дерево узлов как super-дерево, мы сможем отобразить его так:
document ├── shadowRoot1 ├── shadowRoot2 └── shadowRoot3 ├── shadowRoot4 └── shadowRoot5
Здесь корневой узел используется как представитель каждого дерева узлов; корневой узел и само дерево узлов могут быть заменены в объяснениях.
Такое super-дерево (дерево деревьев узлов) мы зовём составным деревом. Концепт составного дерева может быть очень полезен для понимания того, как работает инкапсуляция Shadow DOM.
DOM Standard определяет следующие термины:
- shadow-including tree order
- shadow-including root
- shadow-including descendant
- shadow-including inclusive descendant
- shadow-including ancestor
- shadow-including inclusive ancestor
- closed-shadow-hidden
Чтобы придерживаться инкапсуляции DOM, у нас существует концепция отношения видимости между двумя узлами.
В следующей таблице “-” означает, что “узел A видим из узла B”.
| A \ B | document | a1 | a2 | b1 | c1 | d1 | d2 | e1 | f1 |
|---|---|---|---|---|---|---|---|---|---|
| document | - | - | - | - | - | - | - | - | - |
| a1 | - | - | - | - | - | - | - | - | - |
| a2 | - | - | - | - | - | - | - | - | - |
| b1 | hidden | hidden | hidden | - | hidden | hidden | hidden | hidden | hidden |
| c1 | hidden | hidden | hidden | hidden | - | hidden | hidden | hidden | hidden |
| d1 | hidden | hidden | hidden | hidden | hidden | - | - | - | - |
| d2 | hidden | hidden | hidden | hidden | hidden | - | - | - | - |
| e1 | hidden | hidden | hidden | hidden | hidden | hidden | hidden | - | hidden |
| f1 | hidden | hidden | hidden | hidden | hidden | hidden | hidden | hidden | - |
Например, document виден из любых узлов.
Чтобы отношения видимости было проще понять, есть правило:
- Если узел B может достичь узла A обходом ребра (первая картинка в этом разделе) рекурсивно - A виден из B.
- Однако, ребро (
──/) (отнешния shadowhost-shadowroot) однонаправленно:- Из теневого корня к теневому владельцу -> Окей
- Из теневого владельца к теневому корню -> Запрещено
Другими словами, в составном дереве узел внутреннего дерева может видеть узел внешнего, но не наоборот.
Мы спроектировали (или перепроектировали) несколько Web-facing API, чтобы соблюдать этот принцип. Если вы добавите новый API в веб платформу и Blink, пожалуйста, учитывайте это правило и не пропускайте узел, который должен быть скрыт для веб разработчиков.
Предупреждение: к сожалению, составное дерево имело различные значения в прошлом, и использовалось для обозначения плоского дерева (о котором поговорим позже). Если вы найдете неправильное использование составного дерева в Blink - пожалуйста, почините это.
Далее:
Плоское дерево
Само по себе составное дерево не может быть отображено как есть. С точки зрения отрисовки, Blinkу необходимо собрать дерево макета, которое будет использоваться в качестве входных данных во время фазы отрисовки Дерево макета - это дерево, узлом которого является LayoutObject, который указывает на Node` в дереве узлов, а также на дополнительную вычисляемую информацию о макете.
До того, как в веб платформу был внедрен Shadow DOM, структура дерева макета была схожа со структурой дерева документа, где только только одно дерево узлов, дерево документа, была задействовано.
Теперь, вместе с Shadow DOM, мы имеем составное дерево, которое состоит из нескольких деревьев узлов вместо одного. Это значит, что нам нужно ужать (сделать плоским) составное дерево до одного дерева узлов, называющегося плоским деревом, из которого будет строиться дерево макета.
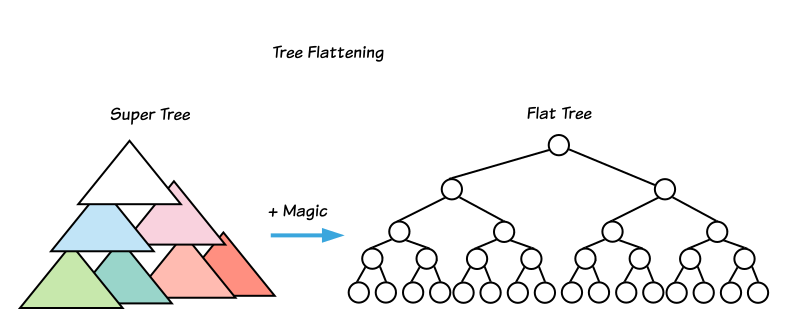
Пример:
document ├── a1 (host) │ ├──/shadowRoot1 │ │ └── b1 │ └── a2 (host) │ ├──/shadowRoot2 │ │ ├── c1 │ │ │ ├── c2 │ │ │ └── c3 │ │ └── c4 │ ├── a3 │ └── a4 └── a5 └── a6 (host) └──/shadowRoot3 └── d1 ├── d2 ├── d3 (host) │ └──/shadowRoot4 │ ├── e1 │ └── e2 └── d4 (host) └──/shadowRoot5 ├── f1 └── f2
Это составное дерево будет ужато до вида плоское дерева из примера ниже (при условии, что в нем нет элементов <slot>):
document ├── a1 (host) │ └── b1 └── a5 └── a6 (host) └── d1 ├── d2 ├── d3 (host) │ ├── e1 │ └── e2 └── d4 (host) ├── f1 └── f2
Мы не можем объяснить конкретный алгоритм ужатия составного дерева в плоское, до пояснения основных концептов слотов и распределения узлов. Игнорируя эффект от <slot>, мы можем иметь следующее простое определение. Плоское дерево может быть определено, как:
- Корень плоского дерева: document
- Для данного узла A который находится в плоском дереве, дочерние элементы определяются рекурсивно и следующим образом:
- Если A is является теневым хостом, то его потомки - потомки теневого корня
- Иначе, потомки A
Слоты и назначения узлов
Посмотрите эту отличную статью о том, как элементы <slot> работают в целом.
Слоты - это плейсхолдеры внутри вашего компонента, которые пользователь может заполнить своей собственной разметкой.
Ниже я привел пару примеров.
Пример 1
Дано следующее составное дерево и назначения слотов
Составное дерево:
A ├──/shadowRoot1 │ ├── slot1 │ └── slot2 ├── B └── C
Назначения слотов:
| slot | slot's assigned nodes |
|---|---|
| slot1 | [C] |
| slot2 | [B] |
Плоское дерево будет выглядеть:
A ├── slot1 │ └── C └── slot2 └── B
Пример 2
Пример посложнее.
Составное дерево:
A ├──/shadowRoot1 │ ├── B │ │ └── slot1 │ ├── slot2 │ │ └── C │ ├── D │ └── slot3 │ ├── E │ └── F ├── G ├── H ├── I └── J
Назначения слотов:
| slot | slot's assigned nodes |
|---|---|
| slot1 | [H] |
| slot2 | [G, I] |
| slot3 | [] (nothing is assigned) |
Плоское дерево будет выглядеть:
A ├── B │ └── slot1 │ └── H ├── slot2 │ ├── G │ └── I ├── D └── slot3 ├── E └── F
- Потомок
slot2,C, не виден в плоском дереве, посколькуslot2имеет не пустые назначенные узлы[G, I], которые используются в качестве потомковslot2в плоском дереве. - Если слоты не имеют назначенных узлов, то дочерние слоты используется как запасное содержимое (fallback contents) плоского дерева, например, потомками
slot3в плоском дереве будутEиF. - Если дочерний узел владельца нигде не назначен, то потомок не используется, например
J
Пример 3
Слот сам по себе может быть назначен другому слоту.
Например, если мы присоединим теневой корень к B и поместим <slot>, slot4 в теневое дерево.
A ├──/shadowRoot1 │ ├── B │ │ ├──/shadowRoot2 │ │ │ └── K │ │ │ └── slot4 │ │ └── slot1 │ ├── slot2 │ │ └── C │ ├── D │ └── slot3 │ ├── E │ └── F ├── G ├── H ├── I └── J
| slot | slot's assigned nodes |
|---|---|
| slot1 | [H] |
| slot2 | [G, I] |
| slot3 | [] (nothing is assigned) |
| slot4 | [slot1] |
Плоское дерево будет выглядеть:
A ├── B │ └── K │ └── slot4 │ └── slot1 │ └── H ├── slot2 │ ├── G │ └── I ├── D └── slot3 ├── E └── F
Пересчет назначения слота
Описано в статье Incremental Shadow DOM.
Обход плоского дерева
Blink не хранит и не поддерживает плоскую структуру данных в памяти. Вместо того, он предоставляет служебный класс [FlatTreeTraversal](https://chromium.googlesource.com/chromium/src/+/master/third_party/blink/renderer/core/dom/flat_tree_traversal.h), который обходит составное дерево в порядке плоского.
Рассматривая пример 3,
FlatTreeTraversal::firstChild(slot1)вернетHFlatTreeTraversal::parent(H)вернетslot1FlatTreeTraversal::nextSibling(G)вернетIFlatTreeTraversal::previousSibling(I)вернетG
API, которые предоставляет FlatTreeTraversal, очень схожи со всеми остальными служебными классами для обхода, такими как NodeTraversal и ElementTraversal.
Путь и ретаргетинг события
DOM Standard определяет, как событие должно отправляться здесь, включая то, как должен вычисляться путь события, однако, я бы не удивлюсь, если описанные там шаги покажутся вам какой-то криптограммой.
В этой секции с помощью нескольких сравнительных примеров я кратно объясню, как событие отправляется и как его путь вычисляется.
По сути, событие отправляется через теневые деревья.
Более сложный пример составного дерева с задействованным слотом:
A └── B ├──/shadowroot-C │ └── D │ ├──/shadowroot-E │ │ └── F │ │ └── slot-G │ └── H │ └── I │ ├──/shadowroot-J │ │ └── K │ │ ├──/shadowroot-L │ │ │ └── M │ │ │ ├──/shadowroot-N │ │ │ │ └── slot-O │ │ │ └── slot-P │ │ └── Q │ │ └── slot-R │ └── slot-S └── T └── U
Назначения слота:
| slot | slot's assigned nodes |
|---|---|
| slot-G | [H] |
| slot-O | [slot-P] |
| slot-P | [Q] |
| slot-R | [slot-S] |
| slot-S | [T] |
Имея это, предположим, что событие выстреливается в U, тогда путем события будет (в обратном порядке):
[U => T => slot-S => slot-R => Q => slot-P => slot-O => shadowroot-N => M => shadowroot-L => K => shadowroot-J => I => H => slot-G => F => shadowroot-E => D => shadowroot-C => B => A]
Грубо говоря, предок события (следующий узел в пути события) вычисляется следующим образом:
- Если узел назначен слот, предком будет являться назначенный слот узла.
- Если узел является теневым корнем, предком будет его теневой хост.
- В остальных случаях, предком будет предок узла.
В случае, приведенном выше, event.target, U, не меняется во время своего жизненного цикла, поскольку U виден из каждого узла. Однако, если событие выстреливается в узле Q, например, то event.target для некоторых узлов в пути события будет скорректирован для инкапсуляции. Этот процесс называется ретаргетингом события.
В таблице ниже представлен путь события для события из Q :
| event.currenttarget | (re-targeted) event.target |
|---|---|
| Q | Q |
| slot-P | Q |
| slot-O | Q |
| shadowroot-N | Q |
| M | Q |
| shadowroot-L | Q |
| K | Q |
| shadowroot-J | Q |
| I | I |
| H | I |
| slot-G | I |
| F | I |
| shadowroot-E | I |
| D | I |
| shadowroot-C | I |
| B | B |